Neither Software Developers nor Users Need to Know about Bits
No, there’s no need for software developers or users of computers to know anything about bits, the 0’s and 1’s at the heart of computing. Bits are a low-level, internal, under-the-hood detail of computers, but not an essential capability that any software developer or user needs to even be aware of or care about, let alone focused on. The misguided focus on bits is a needless and useless distraction. It adds no value and provides no benefits. Okay, there are some exceptions, for low-level software developers, and those working close to the hardware, but they are rare exceptions. This informal paper explores this issue and advocates for moving away from the existing focus on bits for software developers and users.
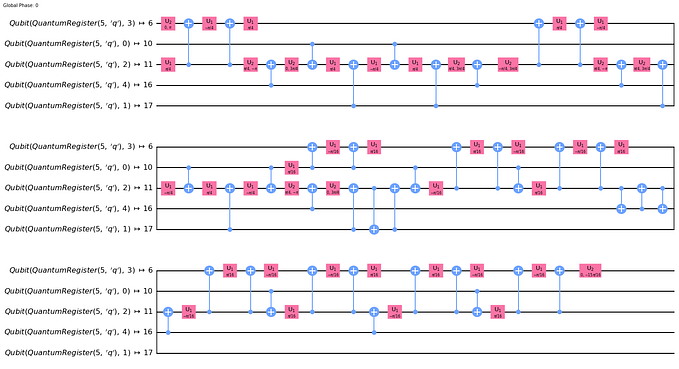
Although this informal paper has nothing to do with quantum computing per se, it serves as the foundation for a future discussion of the same topic in the context of quantum computing, with qubits rather than classical bits. A few brief comments about qubits are included here, at the end, for context.
Topics discussed in this informal paper:
- In a nutshell
- Motivation
- Background
- What is a bit?
- Bit as abstract information vs. storage of bits
- Today: high-level programming languages, data types, and databases
- Today, we focus on data, data types, information, and applications, not bits
- Yes, we need some model of what computing is all about, what’s happening, but that should focus on data, data types, information, and applications, not low-level bits
- High-level abstractions eliminate the need to know about bits
- Absolutely no evidence that knowing anything about bits provides any benefit or value to software developers or users
- Why should caring or not caring about bits matter or be a big deal either way?
- The misguided focus on bits is a needless and useless distraction which adds no value and provides no benefits
- Distinction between bits, binary data, binary values, and Boolean values
- Bit strings
- Rich data types
- Data items and variables
- Data structures
- Control structures
- Operations on high-level data types, values, variables, and control structures are the primary interest for software developers and users
- No real need for bits or references to bits
- Low-level programming
- Hexadecimal notation (hex) is also limited to low-level programming
- Data size
- Units of data size: bytes and words
- The byte is the unit of data
- Bytes are a measure of data size
- Aggregate units of data size: kilobytes, megabytes, gigabytes, terabytes, petabytes, and exabytes
- Memory and storage capacity
- Powers of 2
- Binary data and blobs
- Serial data transmission
- Data transfer rate in bytes or bits per second
- Unfortunately software developers and users do need to know about bytes, but only as a unit and measure of bulk data size
- Sizes of integers
- Sizes of real numbers
- Sign bits
- Arithmetic overflow and underflow
- Bit numbers
- Byte order (endianness)
- Bit vectors and bit arrays
- How big is a character?
- How long is a character string?
- How big is a character string?
- Aren’t pixels just bits? Not quite
- The bits and bytes of media data are generally hidden behind high-level application programming interfaces (APIs)
- Data interchange formats such as HTML, XML, and JSON have further eliminated the need for knowledge about bits
- Overall, high-level languages, rich data types, data structures, databases, and APIs preclude any need for software developers or users to know about bits
- Bits are not relevant to artificial intelligence applications
- Referring to bits has been more a matter of inertia than any technical need
- Computer science without bits? Yes, absolutely!
- Computer scientists will have the same split between high-level and low-level as software developers
- Algorithm designers will generally never need to know about low-level bits
- Bits are more of a cultural phenomenon
- Yes, all of computing ultimately devolves into manipulation of the 0’s and 1’s of bits, but that doesn’t help anyone understand anything
- Teaching software developers and users about bits is counterproductive and outdated
- So, how do we start teaching about computers if we don’t start with the 0’s and 1’s of bits?
- Parallels for quantum computing
- For now, bits are still relevant in quantum computing and in hybrid quantum/classical computing
- But hopefully quantum computing can evolve away from focus on raw qubits and bits
- Alternative titles I considered
- Conclusions
In a nutshell
The highlights of this informal paper:
- Yes, deep knowledge and appreciation of bits was needed in the early days of computing.
- But now, high-level programming languages, rich data types, databases, and applications virtually eliminate any need for a typical software developer or user to know or care about bits.
- Yes, deep knowledge and appreciation of bits is still needed for some low-level software developers and hardware engineers.
- Yes, software developers and users need to know about bytes, but only as a unit of data and as a measure of a bulk aggregate of data, and without any concern about bits within bytes or the size of a byte. Such as the size of a file or a data structure, or a data transmission rate. And for memory and storage usage and capacity.
- Data transfer rates may use bytes or bits per second. Data transfer rate may be the one place where users are directly exposed to bits, as in bits per second. Or megabits per second (Mbps), or gigabits per second (Gbps). But this can easily be remedied — bytes are fine and best, no need for bit rates.
- Software developers and database users may need to work with raw binary data or so-called blobs, but only as an aggregate structure, not the individual bits.
- The availability of high-level abstractions eliminates the need for most people to know anything at all about bits.
- Absolutely no evidence that knowing anything about bits provides any benefit or value to software developers or users. It’s the high-level abstractions that provide the most value to software developers and users. Sure, there are some exceptions for low-level software developers, but they are the rare exception, not the general rule.
- Why should caring or not caring about bits matter or be a big deal either way? The misguided focus on bits is a needless and useless distraction. It adds no value and provides no benefits. A laser focus on the high-level abstractions is what delivers value and benefits. That’s the important focus. That’s the focus that matters.
- The misguided focus on bits is a needless and useless distraction which adds no value and provides no benefits. It distracts from the real value and benefits which come from high-level abstractions, data, data types, information, algorithms, and applications.
- Be careful not to confuse or conflate bits, binary data, binary values, and Boolean values. Boolean true and false, as well as binary values — two values, are still useful and don’t imply use of or rely on raw bits.
- Today, we focus on data, data types, information, and applications, not bits.
- Data interchange formats such as HTML, XML, and JSON have further eliminated the need for knowledge about bits.
- Overall, high-level languages, rich data types, data structures, databases, and APIs preclude any need for software developers or users to know about bits.
- The bits and bytes of media data are generally hidden behind high-level application programming interfaces (APIs).
- Bits are not relevant to artificial intelligence applications. AI is now a very hot area of interest. It is interesting that bits are even less relevant for AI than in past software efforts.
- Referring to bits has been more a matter of inertia than any technical need. It has been quite a few years, even decades, since there was any real need to be aware of bits or even bytes.
- Computer science without bits? Yes, absolutely! At first blush, it might seem absolutely preposterous to approach computer science without bits, but on deeper reflection I do sincerely believe that it makes perfect sense and is the right thing to do. Start with all of the higher-level concepts, including data, data types, and information, and have separate educational modules for lower-level concepts where bits do matter, such as compiler code generation, hardware interfaces, and computer engineering.
- Computer scientists will have the same split between high-level and low-level as software developers. Yes, deep knowledge and appreciation of bits is still needed for some low-level computer scientists, but most computer scientists will be focused on the high-level concepts of data, data types, data structures, control structures, databases, external service APIs, and algorithms without any need to focus on or care about low-level bits.
- Algorithm designers will generally never need to know about low-level bits. Algorithm designers, whether software developers or computer scientists, will be focused on the high-level concepts of data, data types, data structures, control structures, databases, external service APIs, and algorithms without any need to focus on or care about low-level bits. There may be some rare exceptions.
- Bits are more of a cultural phenomenon. Like a virus or parasite. And once it’s entrenched, it stays, and permeates the culture.
- Yes, we need some model of what computing is all about, what’s happening, but that should focus on data, data types, information, and applications, not low-level bits.
- Yes, all of computing ultimately devolves into manipulation of the 0’s and 1’s of bits, but that doesn’t help anyone understand anything. Yes, it is quite true that at the bottom of the stack, at the end of the day, all computing comes down to manipulating data and information in terms of the raw 0’s and 1’s of bits, but… so what? That knowledge doesn’t help anyone — in any way.
- Teaching software developers and users about bits is counterproductive and outdated.
- A higher-level model for teaching people about computing. Without bits.
- For now, bits are still relevant in quantum computing and in hybrid quantum/classical computing, but hopefully quantum computing can evolve away from the focus on raw qubits and classical bits.
Motivation
My motivation in this informal paper is twofold:
- This is an issue which has bothered me for some time. It is distracting people from focusing on higher-level data and processing. Bits are just too low-level of an abstraction to add any real and significant value.
- I am bothered by a comparable issue with qubits in quantum computing. I wanted to lay out my thoughts for classical computing as a foundation for doing the same for quantum computing. Quantum computing should be able to learn from the lessons of classical computing.
Background
Not too many years ago it finally dawned on me that despite all of the talk about bits, very few people, including those designing and developing computer software, needed to know anything at all about bits in even the slightest way, but yet the culture of even the most modern computers was steeped in knowledge of and focus on bits.
It occurred to me that knowledge and discussion of bits was both a distraction and counterproductive.
So, I decided to contemplate the matter further and gradually decided that it was worthy of attention — and correction.
And as I started getting into quantum computing, it struck me even harder that a bit-level focus — now with qubits — was also indeed both an unnecessary distraction and similarly counterproductive.
In the early days of computing it was critical for software developers and users to be aware of every single bit in a computer. It was simply a matter of survival. The requirements in those early days were:
- Bits were a very scarce resource. A precious treasure. Not a cheap commodity.
- The capabilities to operate on bits were very limited.
- Programmers and users alike needed to know every detail of activity within the computer.
- Data was entered as bits.
- Data was processed as bits. Limited high-level operations.
- Data was output as bits.
But as the technology evolved, four things happened:
- Bits proliferated and were no longer a very scarce and precious treasure.
- Higher-level programming and data abstractions emerged which effectively hid much of the bit-level of data and code alike.
- Data models and databases emerged. Further distancing developers and users alike from bit-level structures of data.
- APIs and service interfaces became symbolic. No more need for bits.
What is a bit?
Most people know this, but for completeness…
A bit is the basic unit of information for computers and computing, and digital communications. The value of a bit is either 0 or 1. Something that is easy, cheap, and reliable to implement in hardware. The term bit is a shorthand for binary digit.
For more detail on the concept of a bit:
Bit as abstract information vs. storage of bits
It is sometimes tempting to think of bits as hardware, but bits are really simply abstract information. The 0’s and 1’s of bits are logical values, not physical hardware.
Physical hardware is indeed used to store and manipulate bits of information, but the logical values of the bits are distinct from the physical implementation.
A flip flop or a memory chip or a disk drive or flash drive is capable of storing and manipulating bits but that physical hardware is not the abstract logical information itself.
The same logical bits can be stored in a variety of different hardware devices but still retain their same logical values regardless of the hardware technology.
Today: high-level programming languages, data types, and databases
The reality of today is that software developers and users alike are dealing primarily with high-level abstractions rather than bit-level data.
High-level programming languages offer rich data types and control structures.
Database systems offer high-level data modeling with tables, rows, and columns as well as a similar complement of high-level data types as in high-level programming languages
Today, we focus on data, data types, information, and applications, not bits
Just to hammer home the point, today, most people, both software developers and users, focus on data, data types, information, and applications, not the low-level bits under the hood, the 0’s and 1’s.
Sure, the low-level bits under the hood, the 0’s and1’s, are what make all computers tick, but a knowledge and focus on them is not needed either to develop software or to use a computer or its applications.
Yes, we need some model of what computing is all about, what’s happening, but that should focus on data, data types, information, and applications, not low-level bits
People have to have some sense of what a computer is doing for them. They need to have some model of a computer and computing, but it makes much more sense to focus on data, data types, information, and applications than on the low-level bits under the hood that most software developers and users never personally come into contact with.
The model of computing will be elaborated, briefly, in a subsequent section of this informal paper.
High-level abstractions eliminate the need to know about bits
Summarizing the points of the preceding section a little more abstractly and conceptually:
- The availability of high-level abstractions eliminates the need for most people to know anything at all about bits.
Absolutely no evidence that knowing anything about bits provides any benefit or value to software developers or users
It’s the high-level abstractions that provide the most value and benefit to software developers and users.
There is absolutely no evidence that knowing anything at all about bits provides any benefit or value whatsoever to any software developer or user.
Sure, there are some exceptions for low-level software developers, but they are the rare exception, not the general rule.
Why should caring or not caring about bits matter or be a big deal either way?
The misguided focus on bits is a needless and useless distraction. It adds no value and provides no benefits.
A laser focus on the high-level abstractions is what delivers value and benefits. That’s the important focus. That’s the focus that matters.
The misguided focus on bits is a needless and useless distraction which adds no value and provides no benefits
The misguided focus on bits is a needless and useless distraction which adds no value and provides no benefits.
It distracts from the real value and benefits which come from high-level abstractions, data, data types, information, algorithms, and applications.
Distinction between bits, binary data, binary values, and Boolean values
These are five distinct concepts, which frequently get confused or conflated:
- Bits. Raw 0 and 1, as bit values rather than integers.
- Bit strings. Strings of raw bits, of arbitrary length.
- Binary data. Arbitrary, raw data. May be any combination of data types, including bitstrings, numbers, text, and media. Usually used to manage raw data in bulk rather than attempting to reference individual data items. Such as transferring an entire file. Usually measured in terms of bytes or large multiples of bytes such as kilobytes and megabytes, rather than bits as with bit strings. A bit string of 200 bits would be comparable to binary data of 25 bytes.
- Binary values. Any data which can take one one of two possible values, whether 0 and 1, on and off, yes and no, incomplete and complete, etc. Not to be confused with binary data. A binary value is usually a single data item, and will tend to be stored as a single byte or as an integer.
- Boolean values. Logical true and false. Independent of how they may be stored. May be stored as a binary value, but the data type is Boolean.
This informal paper is focused on bits — and bit strings, not binary data, binary values, or Boolean values.
Boolean logic is of course still very useful and relevant for both software developers and users.
And binary values are common in data and data models.
Binary data is simply a method for managing data in bulk, without attempting to interpret individual data items. And measured as bytes rather than bits.
But raw bits and bit strings are not so useful or relevant to software developers or users in the modern era.
Bit strings
A bit string is simply a sequence of bits.
This is relevant to low-level programming and hardware, but not to most software developers or users.
If you don’t need to know about bits, then you don’t need to know about bit strings.
Rich data types
Modern data can be of rich data types include:
- Integers. Could be 8, 16, 32, or 64 bits, but generally the programmer or user doesn’t need to care about that level of bit-level detail. There are also so-called big number software packages which support very large integers, beyond the range of the hardware integers.
- Real numbers. AKA floating-point numbers. There are also so-called big number software packages which support very large decimal numbers, beyond the range of the hardware floating-point numbers.
- Boolean values. Can be represented as single bits, a byte, or an integer, but not necessarily, and logically they are true and false rather than raw bit values of 1 and 0.
- Characters. A single character.
- Strings. Of text. Or a sequence of characters.
- Dates and times. But may simply be special formats of text, strings.
- Formatted or structured text. Text which follows well-defined rules, such as fixed width, delimiter, and punctuation symbols, rather than arbitrary text or character strings. For example, JSON, XML, and CSV and tab-delimited flat files.
- Data structures. Composite of various data types.
- References to data structures. A pointer or address at the bit level.
Data items and variables
A data item or variable is a storage location containing data of some data type, and typically having a name to distinguish it from other data items and variables.
Yes, the data will be stored as bits, but that’s an irrelevant internal detail.
It’s the high-level data type which matters most.
Data structures
A data structure is a composite structure of two or more data items.
Forms of data structure include include:
- Array. A sequence of data items, called elements, each of the same data type.
- Table. A collection of data items, each of the same data type, and each having a name or key value to distinguish it from the other data items in the table.
- Structure. Or record or row. A sequence of data items, each having a name and its own independent data type.
- List. A collection of structures, each containing a link or pointer to the next structure in the list, and optionally a link or pointer to the previous structure in the list. Also known as a linked list.
- Tree. A hierarchical collection of data items, typically called nodes, with a list of nodes which are at the next level below that node in the hierarchy. The topmost node is known as the root. The bottommost nodes not having any nodes below them are known as leaves or leaf nodes.
- Graph. A collection of nodes, not necessarily in a strict hierarchy. A graph could be a directed graph, an undirected graph, or a directed acyclic graph, representing the relationships between the nodes. A node can connect to any number of other nodes. The connections between nodes are known as edges. An edge can be directional or bidirectional. To be sure, a tree is indeed a graph, but not all graphs are trees.
- Many other specialized forms of data structures. But they are commonly some combination of the other types of data structure listed above.
Control structures
The purpose of control structures are to accommodate five concepts for high-level programming languages:
- Conditional code. Don’t always execute the same code at a point in the logic.
- Looping or iteration. To sequence over an arbitrary amount of data.
- Function calls. To package and invoke logic in named collections called functions or subroutines or procedures. Functions can return a value.
- Evaluate an algebraic expression. A math style equation with constants, variables, and operators.
- Assignments. To evaluate an algebraic expression and store its value in a variable, array element, or named data item.
Operations on high-level data types, values, variables, and control structures are the primary interest for software developers and users
Software developers and users alike can accomplish the vast bulk of their interests using only high-level data types, values, variables, and control structures, with absolutely no need to worry about bits in any way.
No real need for bits or references to bits
Modern data types, data structures, and control structures essentially eliminate all needs for bits or references to bits.
As a general proposition, data can be referenced by a symbolic name with an associated data type — no bits need be referenced directly.
Low-level programming
All of this said, there are still a limited set of use cases where bits and references to bits are needed:
- Direct access to hardware features. Typically in device drivers and some aspects of the kernel of operating systems.
- Compilers. Code generation — generating machine language operations where bits are significant. Converting data values, literal constants, to bit strings for direct use by machine language operations.
- Database internals. A limited core of database software which needs to know how data items are assigned to bit and byte locations in storage.
- Low level tools. Including debuggers, which need to be able directly access data by bits and addresses rather than via named data items.
- Some network service interfaces. Some low-level network service interfaces, protocols, or APIs may be implemented at the bit level. But, most modern services tend to have high-level symbolic interfaces, with no need to use or reference bits.
This is intended for low-level programming, not the work of most software developers or users.
Hexadecimal notation (hex) is also limited to low-level programming
Some programming languages, especially those catering to low-level programming, support hexadecimal notation (hex) to specify specific bit patterns or to directly access bit values.
Again, this is intended for low-level programming, not the work of most software developers or users.
Data size
There are times when the size of a data item or structure are needed, such as when memory is allocated or when data is to be copied in bulk.
Even then, modern programming languages provide non-bit level high-level features to get the size in bytes of any data item or structure.
Units of data size: bytes and words
Even if data is indeed ultimately represented in bits, generally data size is represented in bytes or some larger multiple of bytes.
Each byte is generally eight bits, but ultimately the programmer doesn’t even need to know that, in much the same way that we don’t need to know how long a second of time really is, even if we know that a minute is sixty of those abstract seconds.
Computers are usually designed for optimal operation on some multiple of bytes, typically called a word or a half-word or a long-word or a double-word or a quad-word, which could be two, four, or even eight bytes.
The byte is the unit of data
As a general proposition, the only thing that a software developer or user needs to know about a byte is that it is the unit of data. Analogous to the second being the unit of time.
Any data item will be represented as some number of bytes.
Bytes are a measure of data size
Any data, consisting of some arbitrary number of data items, will be measured as some number of bytes — the data size.
Aggregate units of data size: kilobytes, megabytes, gigabytes, terabytes, petabytes, and exabytes
Larger volumes of data would be represented as bulk aggregates as:
- Kilobytes (KB). Thousands of bytes. Or multiples of 2¹⁰ or 1024 bytes.
- Megabytes (MB). Millions of bytes. Or multiples of 2²⁰ or 1024*1024 bytes.
- Gigabytes (GB). Billions of bytes. Or multiples of 2³⁰ or 1024*1024*1024 bytes.
- Terabytes (TB). Trillions of bytes. Or multiples of 2⁴⁰ or 1024*1024*1024*1024 bytes.
- Petabytes (PB). Quadrillions of bytes. Or multiples of 2⁵⁰ or 1024*1024*1024*1024*1024 bytes.
- Exabytes (EB). Quintillions of bytes. Or multiples of 2⁶⁰ or 1024*1024*1024*1024*1024*1024 bytes.
Sure, the user or developer needs to know about a unit of data called a byte.
Even then, the developer or user doesn’t need to have any clue how a byte is implemented, or exactly what a bit is, or how many bits are in a byte.
Memory and storage capacity
Developers and users do sometimes need to be aware of memory capacity or storage capacity, such as megabytes, gigabytes, terabytes, or larger, but once again, the fact that a byte is eight bits or how a bit works is seldom needed.
But the distinction between one thousand bytes and a kilobyte, or between one million bytes and a megabyte, or between one billion bytes and a gigabyte are not typically going to be very useful to either a software developer or a user.
Powers of 2
Although not strictly about bits per se, powers of 2 are somewhat common, at least for a handful of cases, typically for memory or storage size or capacity or data transmission rates. Common cases of interest are:
- Kilobytes (KB). Multiples of 2¹⁰, but thousands of bytes is generally sufficient.
- Megabytes (MB). Multiples of 2²⁰, but millions of bytes is generally sufficient.
- Gigabytes (GB). Multiples of 2³⁰, but billions of bytes is generally sufficient.
- Terabytes (TB). Multiples of 2⁴⁰, but trillions of bytes is generally sufficient.
The point here is that the big round numbers — thousands, million, billions, and trillions — are typically good enough, and that the precision and technical accuracy of exact powers of 2 simply aren’t needed by software developers or users.
Binary data and blobs
The most common forms of data are numbers, text, and media (images, audio, video.) Purely textual data, even in raw form, is quite readable, directly, simply by reading it. Other forms of data, such as numbers and media, in raw form are quite unreadable, directly, so simply trying to read it is problematic.
Any raw, unreadable data is known as binary data, referring to the fact that reading it, even by software requires accessing the raw bits of the numbers and media, or even any text data which is embedded in the data, intermixed with numeric and media data.
Binary data is typically stored in a file on some storage media.
A blob, or binary large object, is a format of binary data which can be accessed and manipulated as if it were a single data item. This is typically in a database, as a binary data item.
Low-level software developers may indeed need to access the raw bits of binary data or blobs.
But there is typically no need for a software developer to access or directly manipulate the bit-level data within binary data or blobs.
Serial data transmission
At the hardware level, data is typically transmitted serially, one bit at a time, through wires, traces on chips and circuit boards, fiber-optic links, and radio links. Bits can also be transmitted in parallel using multiple wires or traces, such as with data buses.
Bits do indeed matter, greatly, at the hardware level.
But hardware and low-level data transmission are not typically a concern for software developers or users.
Data transfer rate in bytes or bits per second
Data transfer time or rate is sometimes a concern for developers and users.
This will generally be in terms similar to aggregate data size, typically in:
- Kilobytes per second (KBps).
- Megabytes per second (MBps).
- Gigabytes per second (GBps).
Although it is common to couch data transfer in raw bits, such as:
- Kilobits per second (Kbps).
- Megabits per second (Mbps).
- Gigabits per second (Gbps).
This is commonly used to refer to the speed of communications or network links.
Bytes need to be multiplied by eight to get bits.
This may be the one situation where the developer or user needs to know about bits and how many bits are in a byte.
That said, these are generally such large, broad, and nonspecific numbers that most users won’t really sense any real distinction between a gigabyte per second and a gigabit per second, for example, so the distinction can effectively be ignored in most contexts.
The abbreviations use a capital B for bytes, and a lower-case b for bits. For example, GBps for gigabytes per second and Gbps for gigabits per second.
Although, generally, the exact powers of 2 are rarely needed. Generally, the round large numbers — thousands, millions, or billions of bits or bytes — are just as useful as the exact powers or 2 — kilobits/bytes, megabits/bytes, or gigabits/bytes.
As I was writing this text I saw an online video ad for internet service touting “10G” performance, obviously a reference to giga something, ambiguous as to whether it was referring to gigabytes or gigabits per second. I’d presume it implied gigabits per second since that is more common, but the point is that the language and technical details of bits no longer add any useful value to discourse at the user level.
And data transfer rates are not commonly referenced at all at the software level these days, so this is not an issue for software developers. Bits for data transfer rates are simply not needed at all for software developers.
It would be good to migrate data transfer rates from bits per second to bytes per second. There really is no technical benefit to using the former. It’s more of a marketing effort and inertia maintaining an interest in bits per second. After all, a megabit per second does sound much more impressive than 125 kilobytes per second (divide by eight to convert from bits to bytes), as does a gigabit per second compared to 125 megabytes per second.
Unfortunately software developers and users do need to know about bytes, but only as a unit and measure of bulk data size
Yes, there are contexts where software developers and even users need to know about bytes, but only in the sense of it being a unit of data and as a measure of bulk data size, such as the size of a data file or media stream, or a data transfer rate.
Despite this occasional need, there is still no need for software developers or users to know that a byte is eight bits, how the bits are numbered, or anything else about the contents or format of the byte.
Once again, some low-level software developers and hardware developers need to know and care about the details of bytes, but they are the rare exception.
Sizes of integers
In the earliest days of computing, or even later when minicomputers and then microcomputers became popular, it was common to have 16-bit (or 18-bit) and even 8-bit (or 12-bit) representations for integer numbers, and 32-bit integers were an extravagance to be avoided. This made it critical for developers and even users to be aware of the exact size of integers.
But later, as 32-bit integers became the norm, and even 64-bit integers became common, it was much less important for developers and users to even be aware of how many bits were used by a particular integer or how much storage would be required for that particular integer.
Generally, 32 bits is sufficient for most integers, so generally, people need not worry whether their integers might be stored in 32 or 64 bits.
But, in those rare cases when integers don’t fit in 32 bits, such as world population, the national debt, or data storage requirements above four gigabytes, developers and users do need to be aware of 32 vs. 64 bits.
But… they still don’t need to be aware of bits themselves or how many bits are in a byte.
And in many cases the high-level programming language or text-based user interface can accommodate large integers without any need to explicitly say that it’s a 32 vs. 64-bit integer.
Sizes of real numbers
Real numbers are generally represented as so-called floating-point numbers. Developers and users may indeed need to worry about precision and magnitude of the exponent.
But even then, for many applications, minimal precision and magnitude are sufficient so that developers and users need not worry about them — or about bits.
The common form of real numbers, so-called single-precision floating point, accommodates 24 bits of precision, which is roughly seven to eight decimal digits and exponent ranges of roughly ten to the minus 38 to positive 38. That’s sufficient for most applications. This uses a 32-bit (4-byte) format, but even developers don’t need to be aware of that detail.
If an application needs more than seven digits of precision or exponents greater than 38, then double-precision floating point is the next choice, offering a precision of up to 15 to 17 decimal digits and an exponent magnitude of up to 10³⁰⁸. This uses a 64-bit (8-byte) format, but even developers don’t need to be aware of that detail.
There is also a long double format on some machines, using 80 bits rather than 64 bits, but most developers and users won’t need to get down to that level of detail.
And finally, for more demanding applications, quad-precision floating point accommodates up to 113 bits of precision and a 15-bit exponent, offering a precision of up to 33 to 36 decimal digits and an exponent magnitude of up to 10⁴⁹³². This uses a 128-bit (16-byte) format, but even developers don’t need to be aware of that detail.
In short, developers and users may need to be aware of the four different sizes and their limits, but not at the level of bits.
Sign bits
Neither software developers nor users have any need to know or care about how negative numbers are stored or represented in a modern computer.
Yes, there is something called a sign bit, but where it is and how it is interpreted simply isn’t needed to develop software or use a computer or its applications.
Sure, some low-level software developers and hardware developers need to know and care about sign bits, but they are the rare exception rather than the norm.
Arithmetic overflow and underflow
If an arithmetic calculation causes a result which is too big or too small to be represented in a given number of bits, an error called overflow or underflow occurs. Then it’s up to the application to decide how to handle that error condition. And in some cases it explicitly impacts the user, such as causing a visible operation to fail, hopefully in a friendly way, but sometimes in a not-so-friendly way.
Technically, software developers should be cognizant of whether their arithmetic operations could trigger overflow or underflow error conditions, but too commonly, programmers simply ignore that possibility. Generally, it’s not a problem, but on a rare occasion that failure to properly handle arithmetic overflow and underflow error conditions could cause a malfunction of the software or even cause a catastrophic failure in the real world.
The number of bits used by an integer or real number will determine whether a given arithmetic operation will cause an overflow or underflow condition. Generally, the software developer could simply switch to a data type with more bits to avoid the possibility of an error.
Despite all of this, the software developer (or user) still doesn’t need to know the exact number of bits needed, but simply which data types to use to cover the full range of decimal numeric values that can be expected in the data or in arithmetic calculations.
Bit numbers
Yes, bits are numbered, in bytes, integers, floating-point numbers, characters, and bit strings, but once again, only some low-level software developers and hardware developers need to know and care about bit numbers, and they are the rare exception rather than the norm.
Byte order (endianness)
In some contexts, the order of bytes in integers and floating-point numbers can vary. There are concepts such as big-endian, little-endian, and collectively endianness, but once again, only some low-level software developers and hardware developers need to know and care about endianness, and they are the rare exception rather than the norm.
Bit vectors and bit arrays
Normal data structures such as arrays and lists are sufficient for most applications, but for some more extreme applications bit vectors might be needed — or at least a software developer might imagine that they are needed. They might in fact be needed in some of these extreme cases, but these are too rare to be considered part of the normal toolkit of typical software developers.
The terms bit vector and bit array are synonymous.
What is a bit vector? In essence, a bit vector is simply an array of Boolean values, or at least functionally equivalent to an array of Boolean values. The only difference from an array of Boolean values would be that each bit is allocated a single bit in a byte, eight bits in a byte, rather than a full byte (or more.)
Some programming languages might have an explicit bit vector data type which is optimized for a single bit for each bit value, eight bits in a byte. In this case, no special or additional effort is required of the software developer — they can use the bit vector the same way an array of Booleans (or any other type) would be used.
If the programming language doesn’t have a native bit vector data type, the software developer can roll their own by using an array of integers and then using bit operations to examine or modify individual bits as desired.
But for many use cases, a simple array of Boolean values is sufficient. No need to worry about lower-level bits.
The point here is that although bit vectors are sometimes needed (or imagined to be needed), this is the rare exception rather than the norm.
How big is a character?
In the old days, everybody knew that a character of text was represented by a single byte and that byte had eight bits.
Actually, in the really old days, like when I was starting in computing, we used seven bits or even six bits for characters. We called them ASCII characters or six-bit for 6-bit characters, to put five or six characters respectively in a 36-bit word. We even had RADIX 50 to squeeze six six-bit characters and four flag bits into a single 36-bit word. But that was in the old days (1970’s). Long Ago. Literally, 50 years ago.
These days, the picture is mixed. Sure, most text characters are represented by a single 8-bit byte, but that is not always the case.
The current standard for text characters is Unicode, which supports far more than 256 distinct characters. In fact, a Unicode character could require up to 32 bits.
The common characters, up to 256 of them, are referred to as ISO Latin-1.
Although an individual Unicode character can require up to 32 bits, strings of characters can be encoded in a more compact format since many or most characters can be represented in eight bits or sixteen bits.
The Unicode Transformation Format (UTF) governs how characters are packed into character strings. There are three of these formats:
- UTF-32. Each character requires 32 bits.
- UTF-16. Each character requires one or two 16-bit values.
- UTF-8. Each character requires between one and four one-byte 8-bit values.
Generally, neither a software developer nor a user will know how many bytes are required to represent each character.
Even for ISO Latin-1, some characters will require two bytes rather than a single 8-bit byte.
All of that said, most developers and users won’t need to have any knowledge of either the encoding format or how many bits or bytes are needed for each character or the entire string.
The point is that neither developers nor users have any need to know about bits or bytes when working with characters and character strings.
How long is a character string?
Generally, the length of a character string will be measured in characters rather than bytes or bits.
Few developers and no users will have to know how many bits or bytes are needed to represent a character string.
How big is a character string?
While the length of a character string is the count of characters in the string, the size of the character string is the number of bytes taken up by all of the characters, some of which may require multiple bytes due to Unicode coding formats.
Aren’t pixels just bits? Not quite
Pixels of display screens do seem a little bit-like, being just a tiny dot, but there’s more to each of those tiny dots than just a single 0 or 1 bit. Each pixel has a color, and each color takes some number of bits to represent the color.
In general, users and software developers alike won’t have a clue as to how many bits are used to represent the color of each pixel.
In fact, not only do I personally not have a clue how many bits are used to represent color for each pixel of the 4K HDR touchscreen display on my current laptop right in front of me at this moment, I can’t even remember how many years it’s been since I did know.
I vaguely recall that many years ago my display used 16 bits for 65,536 colors. Higher-end displays used 24 bits and some used 32 bits.
So, my current laptop display could use 24 bits for each pixel, or 32 bits, or… maybe some other number of bits per pixel.
The point here is that I neither know nor care, and more to the point of this informal paper, I don’t need to know.
The bits and bytes of media data are generally hidden behind high-level application programming interfaces (APIs)
There are certainly plenty of bits and bytes required to represent media data, such as:
- Photographs.
- Scanned images.
- Scanned documents.
- Generated graphical images.
- Printed documents.
- Audio.
- Video.
Including metadata, beyond the actual media content.
But generally, the bits and bytes and internal data formats of media data are hidden behind high-level application programming interfaces (API’s).
Sure, there are some low-level software developers who will of necessity know about the byte and bit-level formats of media data and metadata, but they are the rare exception rather than the norm.
Data interchange formats such as HTML, XML, and JSON have further eliminated the need for knowledge about bits
Modern data interchange formats, such as HTML, XML, and JSON have focused on symbolic data, so that raw bits have become even more irrelevant.
Overall, high-level languages, rich data types, data structures, databases, and APIs preclude any need for software developers or users to know about bits
Honestly, there is no real need for software developers or users to know anything about bits these days with all of the high-level languages, rich data types, data structures, databases, and APIs which are available at our fingertips.
Bits are not relevant to artificial intelligence applications
AI is now a very hot area of interest. It is interesting that bits are even less relevant for AI than in past software efforts, despite its increased complexity relative to past software.
High-level data types and data structures handle the complexity without any need to focus on raw, low-level bits.
Other application areas can benefit from lessons learned with AI.
Referring to bits has been more a matter of inertia than any technical need
In truth, it has been quite a few years, even decades, since there was any real need to be aware of bits or even bytes.
It has been more a matter of inertia than any technical need.
But my feeling and view of late is that the time has come to move beyond that old, unneeded baggage.
Computer science without bits? Yes, absolutely!
At first blush, it might seem absolutely preposterous to approach computer science without bits, but on deeper reflection I do sincerely believe that it makes perfect sense and is the right thing to do.
First, most of this informal paper covers topics very relevant to computer science, but clearly bits are not needed to cover and work in those topic areas.
But as noted in this informal paper, yes, there are areas where knowing about and working with bits is a necessity. Particularly low-level software, code generation for compilers, working close to the hardware, hardware engineers, computer engineers, and maybe some others, but they are rare relative to the vast majority of software developers and users.
As a later section summarizes, computing can be introduced in terms of data, data types, information, and applications, none of which requires bits.
Separate educational modules can introduce bits for all of those exception cases:
- Low-level software development. Including device drivers.
- Code generation for compilers. Generating machine language instructions.
- Computer engineering. Computer architecture, machine language. Not clear how much of this would fall under computer science as opposed to electrical engineering. I think it belongs in both, or at least a significant subset does.
- Low-level tools. Including debuggers.
- Database internals. A limited core of database software which needs to know how data items are assigned to bit and byte locations in storage.
- Maybe some others.
It all seems logical to me.
Start people out with the high-level concepts before lifting the hood and diving into what’s under the hood.
Computer scientists will have the same split between high-level and low-level as software developers
As a general proposition, computer scientists will have the same split between high-level and low-level as for software developers.
A deep knowledge and appreciation of bits is still needed for some low-level computer scientists, such as for the areas listed in the preceding section, especially when considerations of computer architecture are involved.
But most computer scientists will be focused on high-level concepts of data, data types, data structures, control structures, databases, external service APIs, and algorithms without any need to focus on or care about low-level bits.
Algorithm designers will generally never need to know about low-level bits
As a general proposition, algorithm designers will never need to know about low-level bits.
Whether they are software developers or computer scientists, algorithm designers will be focused on the high-level concepts of data, data types, data structures, control structures, databases, external service APIs, and algorithms without any need to focus on or care about low-level bits.
There may be some rare exceptions.
Bits are more of a cultural phenomenon
Obsessing over bits is more of a cultural phenomenon than a technical requirement.
Some people are proud of the fact that they know about bits and bytes.
But it is pride and ego that has driven this contrived need for bits and bytes, not technical necessity.
The concept of bits is like a virus or parasite. And once it’s entrenched, it stays, and permeates the culture.
Yes, all of computing ultimately devolves into manipulation of the 0’s and 1’s of bits, but that doesn’t help anyone understand anything
Yes, it is quite true that at the bottom of the stack, at the end of the day, all computing comes down to manipulating data and information in terms of the raw 0’s and 1’s of bits, but… so what? That knowledge doesn’t help anyone — in any way.
It simply doesn’t help anyone, software developers or users alike, to focus any attention on those 0’s and 1’s of bits, when what they really care about is the data, the data types, the information, and the applications, the numbers, the text, and the media.
Teaching software developers and users about bits is counterproductive and outdated
There is literally no useful purpose served by teaching software developers and users about bits.
Electrical engineers and computer engineers of course need to be aware of bits.
A limited set of low-level software professionals still need to be aware of bits, but that should be viewed as a specialized niche of knowledge for those few professionals rather than general knowledge for all software developers and all users.
Education on computers should focus on rich data types, not the low-level language of the machine.
Much as modern software developers are not taught to start with machine language or assembly language (or at least they shouldn’t be!), they shouldn’t be taught to start with bits for data.
The term bit shouldn’t even be in the vocabulary of software developers or users anymore at this stage. It’s inertia again, not a meaningful technical need.
So, how do we start teaching about computers if we don’t start with the 0’s and 1’s of bits?
Even if we can escape from teaching people about bits in order to learn about computing, the question arises as to what exactly they should be taught.
In particular, people need to be given a model of what computing is all about.
Here’s a simplified outline for such a model:
- Start with the concept of data and information and how to organize and manipulate it. That’s all computing is all about. That’s the model of computing. The bits, the 0’s and 1’s are all a distraction.
- Start with realistic data — information. Numbers, text, and media. Data and information that people can relate to in their daily lives.
- Organizing data — information. Lists, tables, files, directories and folders, databases, links to other data. Servers. Networking.
- Basic processing. Arithmetic. Sorting. Searching. Inserting. Replacing. Editing. Deleting. Statistical analysis. Analytics.
- Memory. Currently active.
- Storage. Persistent. Long term.
- Operating systems.
- Basic input and output. Keyboard. Pointing device. Screen. Touch input. Scanners. Printers.
- Media input and output. Scanning images. Displaying images. Microphones. Speakers. Cameras — still and video. Phone calls. Watching and listening to media. Robotics.
- The basic input, process, and output model.
- Organizing and managing information at the user level. File systems. Databases. Repositories.
- Security. Access control. Logging. Auditing.
- Focus on applications.
- Productivity applications.
- Social media.
- Programming and software development. Logic. Data modeling. Algorithms. Applications. Services.
- Databases.
- Libraries of shared code.
- External service APIs. Such as web services.
- Application development.
- Software development tools.
- Electronics, electrical engineering, and computer engineering.
As noted, very few of those areas require any knowledge or even awareness of bits.
Make data, information, and applications the focus, in terms that software developers and users alike would naturally relate to without any a priori knowledge of what is going on under the hood or inside the chips.
Parallels for quantum computing
A large part of the motivation for this informal paper was to establish a baseline and foundation for pursuing the same line of thinking with quantum computing, but with qubits rather than bits.
The parallels will not be precise, but there are at least some similarities.
Quantum computing is at a much earlier stage. Maybe even comparable to only the 1940’s for classical computing. Very primitive. Very unsophisticated.
But evolution and advances in quantum computing could bring at least a rough convergence between classical computing and quantum computing, between bits and qubits. Or at least a partial convergence.
Stay tuned for a follow-up informal paper.
For now, bits are still relevant in quantum computing and in hybrid quantum/classical computing
Despite its focus on qubits, classical bits are still very relevant in quantum computing.
Maybe even the central focus, at least for now.
The basis states of qubits are 0 and 1, just as with classical bits. Couched as |0> and |1>.
The wave function of an isolated qubit is couched in terms of probability amplitudes of those two basis states — bit values 0 and 1.
When a qubit is measured, its quantum state will collapse into a classical bit state of 0 or 1.
And the wave function of an entangled collection of qubits consists of a collection of product states, each of which is a bit string — with an associated probability amplitude, one bit in the bit string for each entangled qubit, up to 2^n bit strings for n entangled qubits.
None of this has any bearing on classical computing, but is still relevant to hybrid quantum/classical computing, the intersection of quantum computing and classical computing.
But hopefully quantum computing can evolve away from focus on raw qubits and bits
That said, in a separate informal paper I will argue for a comparable evolution or abstraction away from raw qubits, bit values, and bit strings towards higher-level abstractions which don’t involve qubits or bits. But for now, qubits and bits both still remain relevant in quantum computing and in hybrid quantum/classical computing.
The most meaningful, productive, and beneficial effort for quantum computing will be to focus on quantum parallelism as the key, essential, central concept — not qubits or quantum effects. Yes, qubits and quantum states are required, and the quantum effects of superposition, entanglement, interference, and measurement are essential for achieving quantum parallelism, but it is the high-level concept of quantum parallelism which deserves the central focus, not the lower-level concepts.
And quantum computing deserves the quantum equivalent of data, data types, and information. With just raw qubits, we are forced to include the classical concept of bits. By shifting from qubits and quantum states to data, data types, and information, classical bits would no longer be relevant to quantum computing.
At a very minimum, starting off education for quantum computing by comparing qubits with classical bits — as virtually every introduction to quantum computing does — is a very bad start. Quantum parallelism is the best start, plus the quantum equivalents to data data types, and information.
A focus on high-level algorithmic building blocks, based on the quantum equivalents of data, data types, and information, will also be a much better start than focusing on raw qubits.
Alternative titles I considered
For my own future reference, here are alternative titles which I considered for this informal paper:
- Neither Software Developers nor Users Need to Know about Bits
- Neither Software Developers nor Users Need to Know anything about Bits
- There Is No Good Reason for Software Developers or Users to Know about Bits
- Virtually nobody needs to know about bits
- Virtually nobody needs to know about bits these days
- Nobody needs to know about bits these days
- Bits considered harmful
Conclusions
- Yes, deep knowledge and appreciation of bits was needed in the early days of computing.
- But now, high-level programming languages, rich data types, databases, and applications virtually eliminate any need for a typical software developer or user to know or care about bits.
- Yes, deep knowledge and appreciation of bits is still needed for some low-level software developers and hardware engineers.
- Yes, software developers and users need to know about bytes, but only as a unit of data and as a measure of a bulk aggregate of data, and without any concern about bits within bytes or the size of a byte. Such as the size of a file or a data structure, or a data transmission rate. And for memory and storage usage and capacity.
- Data transfer rates may use bytes or bits per second. Data transfer rate may be the one place where users are directly exposed to bits, as in bits per second. Or megabits per second (Mbps), or gigabits per second (Gbps). But this can easily be remedied — bytes are fine and best, no need for bit rates.
- Software developers and database users may need to work with raw binary data or so-called blobs, but only as an aggregate structure, not the individual bits.
- The availability of high-level abstractions eliminates the need for most people to know anything at all about bits.
- Absolutely no evidence that knowing anything about bits provides any benefit or value to software developers or users. It’s the high-level abstractions that provide the most value to software developers and users. Sure, there are some exceptions for low-level software developers, but they are the rare exception, not the general rule.
- Why should caring or not caring about bits matter or be a big deal either way? The misguided focus on bits is a needless and useless distraction. It adds no value and provides no benefits. A laser focus on the high-level abstractions is what delivers value and benefits. That’s the important focus. That’s the focus that matters.
- The misguided focus on bits is a needless and useless distraction which adds no value and provides no benefits. It distracts from the real value and benefits which come from high-level abstractions, data, data types, information, algorithms, and applications.
- Be careful not to confuse or conflate bits, binary data, binary values, and Boolean values. Boolean true and false, as well as binary values — two values, are still useful and don’t imply use of or rely on raw bits.
- Today, we focus on data, data types, information, and applications, not bits.
- Data interchange formats such as HTML, XML, and JSON have further eliminated the need for knowledge about bits.
- Overall, high-level languages, rich data types, data structures, databases, and APIs preclude any need for software developers or users to know about bits.
- The bits and bytes of media data are generally hidden behind high-level application programming interfaces (APIs).
- Bits are not relevant to artificial intelligence applications. AI is now a very hot area of interest. It is interesting that bits are even less relevant for AI than in past software efforts.
- Referring to bits has been more a matter of inertia than any technical need. It has been quite a few years, even decades, since there was any real need to be aware of bits or even bytes.
- Computer science without bits? Yes, absolutely! At first blush, it might seem absolutely preposterous to approach computer science without bits, but on deeper reflection I do sincerely believe that it makes perfect sense and is the right thing to do. Start with all of the higher-level concepts, including data, data types, and information, and have separate educational modules for lower-level concepts where bits do matter, such as compiler code generation, hardware interfaces, and computer engineering.
- Computer scientists will have the same split between high-level and low-level as software developers. Yes, deep knowledge and appreciation of bits is still needed for some low-level computer scientists, but most computer scientists will be focused on the high-level concepts of data, data types, data structures, control structures, databases, external service APIs, and algorithms without any need to focus on or care about low-level bits.
- Algorithm designers will generally never need to know about low-level bits. Algorithm designers, whether software developers or computer scientists, will be focused on the high-level concepts of data, data types, data structures, control structures, databases, external service APIs, and algorithms without any need to focus on or care about low-level bits. There may be some rare exceptions.
- Bits are more of a cultural phenomenon. Like a virus or parasite. And once it’s entrenched, it stays, and permeates the culture.
- Yes, we need some model of what computing is all about, what’s happening, but that should focus on data, data types, information, and applications, not low-level bits.
- Yes, all of computing ultimately devolves into manipulation of the 0’s and 1’s of bits, but that doesn’t help anyone understand anything. Yes, it is quite true that at the bottom of the stack, at the end of the day, all computing comes down to manipulating data and information in terms of the raw 0’s and 1’s of bits, but… so what? That knowledge doesn’t help anyone — in any way.
- Teaching software developers and users about bits is counterproductive and outdated.
- A higher-level model for teaching people about computing. Without bits.
- For now, bits are still relevant in quantum computing and in hybrid quantum/classical computing, but hopefully quantum computing can evolve away from the focus on raw qubits and classical bits.
For more of my writing: List of My Papers on Quantum Computing.